TLDR: Favor the .assign method, and you will not deal with SettingWithCopyWarning issues.
Bad Code
Today I'm going to show you the solution to the dreaded
SettingWithCopyWarning error that you eventually run into, but no
one seems to explain it or give you a solution that you can understand.
I just saw another article discussing it today and thought I would share the best solution (that no one else talks about).
Here's the data referred to in the above article:
df = pd.DataFrame({
'x':[1,5,4,3,4,5],
'y':[.1,.5,.4,.3,.4,.5],
'w':[11,15,14,13,14,15]})
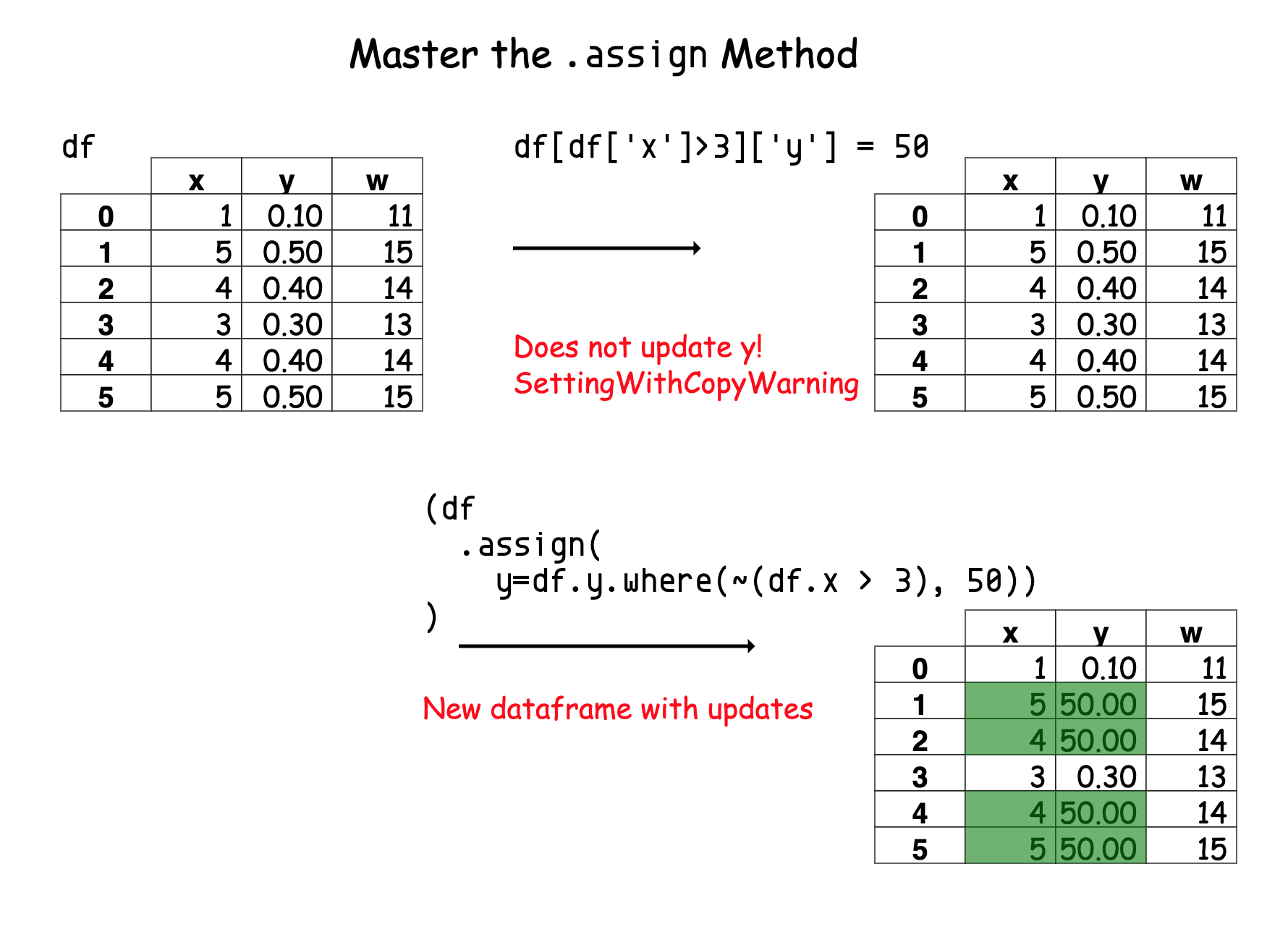
The quest with this toy data is to change all values in the y column to 50 when the x column is greater than 3. Most try to do this by using indexing operations to filter out the appropriate rows and then doing an index assignment.
If you do an index operation directly on df, the update does not work. And you see
the dreaded SettingWithCopyWarning warning:
df[df['x']>3]['y'] = 50
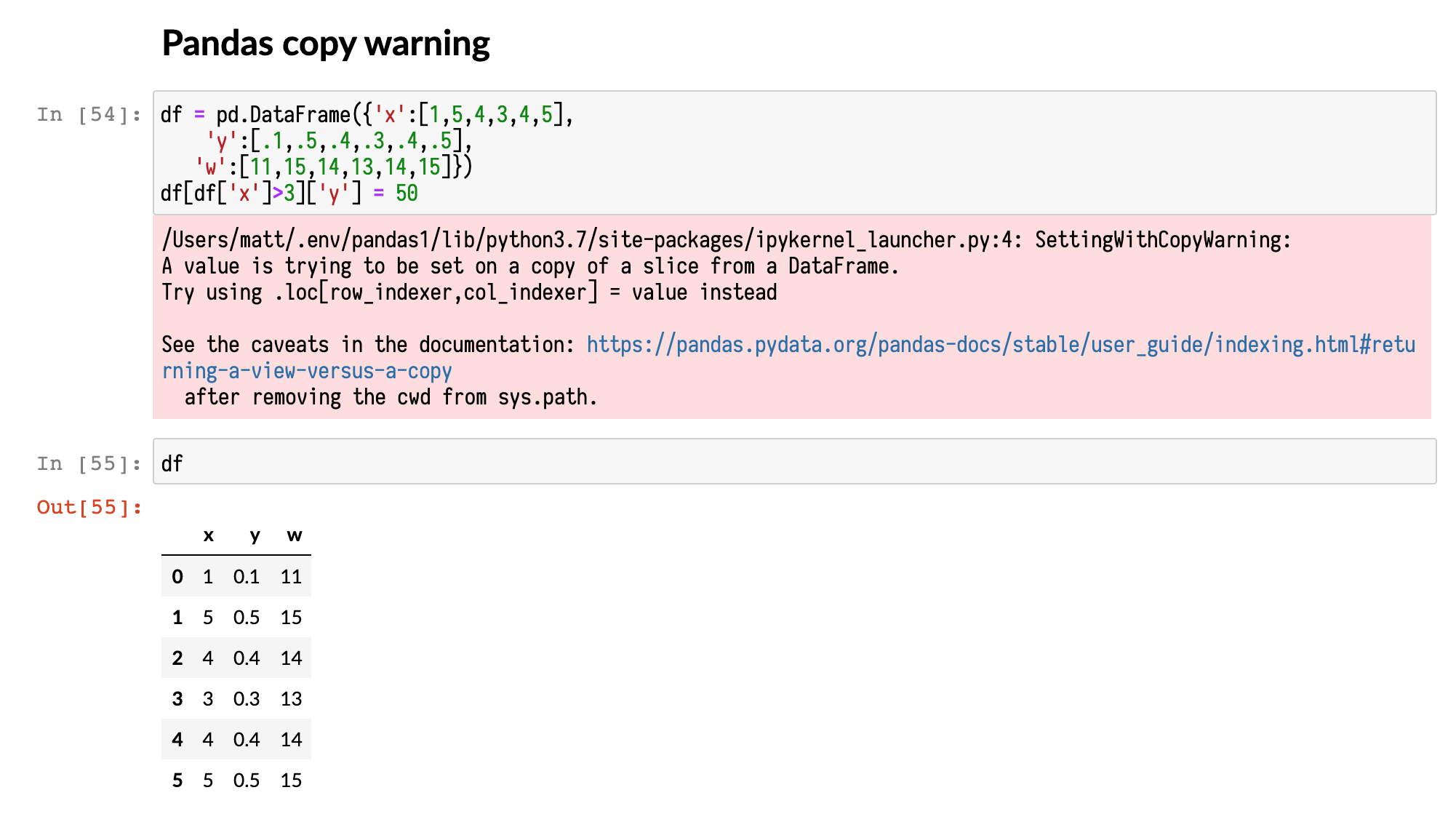
The issue with this code is that df[df['x']>3] does not return the original dataframe. So the subsequent index assignment, ['y'] = 50, updates the new dataframe and not df. In effect, you create a new dataframe, assign to it, and do not capture it to a variable, so it is immediately available to be garbage collected.
The warning includes a tip to use .loc for indexing instead. Here is an example that works:
df.loc[df['x']>3,'y'] = 50
I recommend that you do not use this solution. I have a better solution below.
Three Rules for Better Pandas
However, I'll add three more rules of thumb that I have found to make pandas code easier to understand and less prone to errors:
- Do not mutate objects
- Favor chaining operations
- Do not use assignment (the
=operator) in pandas
The above code mutates df. However, most pandas operations do not mutate. For feeble-minded people like me, mixing mutation and immutability leads to confusing code and errors. My preferred solution to the above is this code:
df.assign(y=df.y.where(~(df.x > 3), 50))
In fact, whenever I create a new column (or update one) in pandas, I try to do it with the .assign method. This code also requires understanding the .where, method which takes some getting used to but obeys my three rules above.
A Chained Example
Here is an example from Chapter 5 of the The Pandas 1.x Cookbook. This code loads vehicle data from the fueleconomy.gov website. It applies a chain of operations to the dataframe when creating the data variable.
First, it filters out the makes that are Ford, Tesla, BMW, or Toyota with this line [fueleco.make.isin(makes)]. (It could
have used .loc here as well). Next, it assigns a column, SClass, that is
created from an inlined function (a lambda function) with this line .assign(SClass=.... If you use a function
with the .assign method, you have access to the intermediate dataframe, referred to as df_ in the code. The lambda function dispatches to the generalize function.
The generalize function is a function I use all over the place when refining data. It takes a column and a list of tuples with match names and new values in it. It also accepts a default value. It loop over the list returns a new series where the match names are replaced with the new names. If there is no match, the default value is used. This function can be useful if you have a bunch of
categorical data and want to limit it to a smaller subset:
url = 'https://github.com/mattharrison/datasets/raw/master/data/vehicles.csv.zip'
fueleco = pd.read_csv(url)
def generalize(ser, match_name, default):
seen = None
for match, name in match_name:
mask = ser.str.contains(match)
if seen is None:
seen = mask
else:
seen |= mask
ser = ser.where(~mask, name)
ser = ser.where(seen, default)
return ser
makes = ['Ford', 'Tesla', 'BMW', 'Toyota']
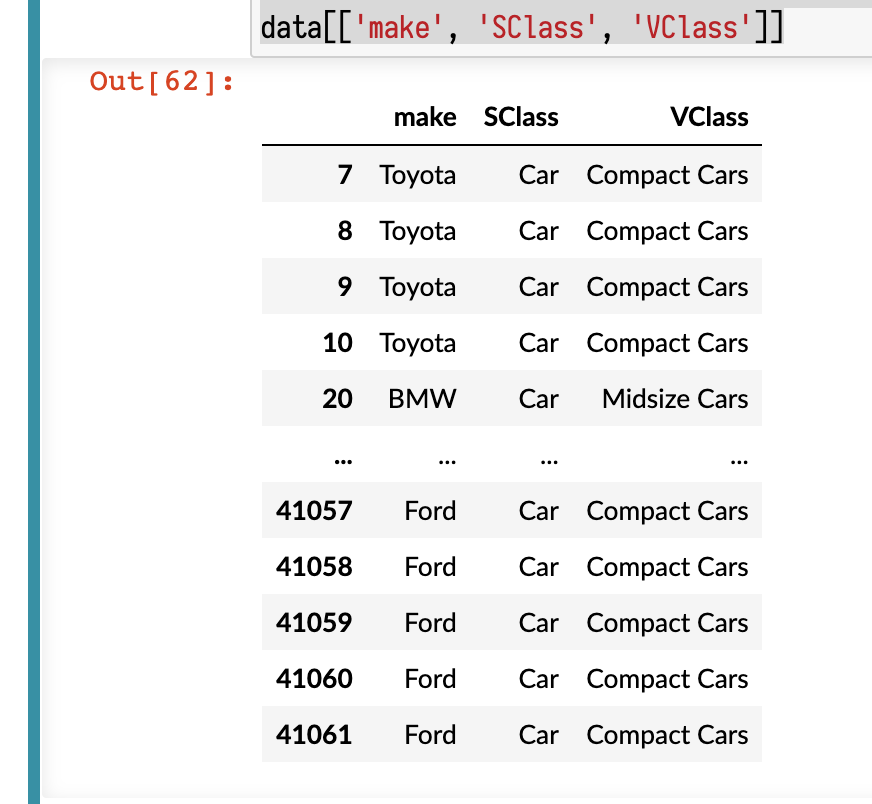
data = (fueleco
[fueleco.make.isin(makes)]
.assign(SClass=lambda df_: generalize(df_.VClass,
[('Seaters', 'Car'), ('Car', 'Car'), ('Utility', 'SUV'),
('Truck', 'Truck'), ('Van', 'Van'), ('van', 'Van'),
('Wagon', 'Wagon')], 'other'))
)
data[['make', 'SClass', 'VClass']]
Conclusion
Try not to mutate data when using pandas. Even the pandas core developers say that you should not use mutation. If you use method chaining (note that index assignment does not work with chaining!), you will not mutate data. You will not have to deal with the SettingWithCopyWarning. Your code will be easier to read because it will read like processing steps.
If you want to see examples of pandas code that obey these rules see my latest book, Effective Pandas or follow me on twitter where I rant on such topics.