A Series is used to model one-dimensional data, similar to a list in Python. The Series object also has a few more bits of data, including an index and a name. A common idea through pandas is the notion of an axis. Because a series is one dimensiona-, it has a single axis—the index.
Below is a table of counts of songs artists composed. We will use this to explore how the series type functions:
| Artist | Data |
|---|---|
| 0 | 145 |
| 1 | 142 |
| 2 | 38 |
| 3 | 13 |
If you wanted to represent this data in pure Python, you could use a data structure similar to the one that follows. It is a dictionary that has a list of the data points stored under the 'data' key. In addition to an entry in the dictionary for the actual data, there is an explicit entry for the corresponding index values for the data (in the 'index' key), as well as an entry for the name of the data (in the 'name' key):
>>> ser = {
... 'index':[0, 1, 2, 3],
... 'data':[145, 142, 38, 13],
... 'name':'songs'
... }
The get function defined below can pull items out of this data structure based on the index:
>>> def get(ser, idx): ... value_idx = ser['index'].index(idx) ... return ser['data'][value_idx] >>> get(ser, 1) 142
Note
The code samples in this book are shown as if they were typed directly into an interpreter. Lines starting with >>> and ... are interpreter markers for the input prompt and continuation prompt respectively. Lines that are not prefixed by one of those sequences are the output from the interpreter after running the code.
The Python interpreter will print the return value of the last invocation (even if the print statement is missing) automatically. If you desire to use the code samples found in this book, leave the interpreter prompts out.
The index abstraction
This double abstraction of the index seems unnecessary at first glance—a list already has integer indexes. But there is a trick up pandas' sleeves. By allowing non-integer values, the data structure supports other index types such as strings, dates, as well as arbitrarily ordered indices or even duplicate index values.
Below is an example that has string values for the index:
>>> songs = {
... 'index':['Paul', 'John', 'George', 'Ringo'],
... 'data':[145, 142, 38, 13],
... 'name':'counts'
... }
>>> get(songs, 'John')
142
The index is a core feature of pandas’ data structures given the library’s past in analysis of financial data or time series data. Many of the operations performed on a Series operate directly on the index or by index lookup.
The pandas Series
With that background in mind, let’s look at how to create a Series in pandas. It is easy to create a Series object from a list:
>>> import pandas as pd >>> songs2 = pd.Series([145, 142, 38, 13], ... name='counts') >>> songs2 0 145 1 142 2 38 3 13 Name: counts, dtype: int64
When the interpreter prints our series, pandas makes a best effort to format it for the current terminal size. The leftmost column is the index column which contains entries for the index. The generic name for an index is an axis, and the values of the index—0, 1, 2, 3—are called axis labels. The two-dimensional structure in pandas—a DataFrame—has two axes, one for the rows and another for the columns.

The parts of a Series.
The rightmost column in the output contains the values of the series—145, 142, 38, and 13. In this case, they are integers (the console representation says dtype: int64, dtype meaning data type, and int64 meaning 64-bit integer), but in general values of a Series can hold strings, floats, booleans, or arbitrary Python objects. To get the best speed (and to leverage vectorized operations), the values should be of the same type, though this is not required.
It is easy to inspect the index of a series (or data frame), as it is an attribute of the object:
>>> songs2.index RangeIndex(start=0, stop=4, step=1)
The default values for an index are monotonically increasing integers. songs2 has an integer-based index.
Note
The index can be string based as well, in which case pandas indicates that the datatype for the index is object (not string):
>>> songs3 = pd.Series([145, 142, 38, 13], ... name='counts', ... index=['Paul', 'John', 'George', 'Ringo'])
Note that the dtype that we see when we print a Series is the type of the values, not of the index:
>>> songs3 Paul 145 John 142 George 38 Ringo 13 Name: counts, dtype: int64
When we inspect the index attribute, we see that the dtype is object:
>>> songs3.index # doctest: +NORMALIZE_WHITESPACE Index(['Paul', 'John', 'George', 'Ringo'], dtype='object')
The actual data for a series does not have to be numeric or homogeneous. We can insert Python objects into a series:
>>> class Foo: ... pass >>> ringo = pd.Series( ... ['Richard', 'Starkey', 13, Foo()], ... name='ringo') >>> ringo # doctest: +SKIP +NORMALIZE_WHITESPACE 0 Richard 1 Starkey 2 13 3 <__main__.Foo instance at 0x...> Name: ringo, dtype: object
In the above case, the dtype-datatype-of the Series is object (meaning a Python object). This can be good or bad.
The object data type is used for strings. But, it is also used for values that have heterogeneous types. If you have just numeric data in a series, you wouldn't want it stored as a Python object, but rather as an int64 or float64, which allow you to do vectorized numeric operations.
If you have time data and it says it has the object type, you probably have strings for the dates. Using strings instead of date types is bad as you don't get the date operations that you would get if the type were datetime64[ns]. Strings, on the other hand, are stored in pandas as object. Don't worry; we will see how to convert types later in the book.
The NaN value
A value that may be familiar to NumPy users, but not Python users in general, is NaN. When pandas determines that a series holds numeric values, but it cannot find a number to represent an entry, it will use NaN. This value stands for Not A Number and is usually ignored in arithmetic operations. (Similar to NULL in SQL).
Here is a series that has NaN in it:
>>> import numpy as np >>> nan_ser = pd.Series([2, np.nan], ... index=['Ono', 'Clapton']) >>> nan_ser Ono 2.0 Clapton NaN dtype: float64
Note
One thing to note is that the type of this series is float64, not int64! The type is a float because float64 supports NaN, which int64 does not. When pandas sees numeric data (2) as well as the None, it coerced the 2 to a float value.
Below is an example of how pandas ignores NaN. The .count method, which counts the number of values in a series, disregards NaN. In this case, it indicates that the count of items in the Series is one, one for the value of 2 at index location Ono, ignoring the NaN value at index location Clapton:
>>> nan_ser.count() 1
Note
If you load data from a CSV file, an empty value for an otherwise numeric column will become NaN. Later, methods such as .fillna and .dropna will explain how to deal with NaN.
None, NaN, nan, and null are synonyms in this book when referring to empty or missing data found in a pandas series or data frame.
Optional Integer Support for NaN
As of pandas 0.24, there is optional support for the integer type to hold NaN values. The documentation calls this type the nullable integer type. When you create a series, you can pass in dtype='Int64' (note the capitalization):
>>> nan_ser2 = pd.Series([2, None], ... index=['Ono', 'Clapton'], ... dtype='Int64') >>> nan_ser2 Ono 2 Clapton <NA> dtype: Int64
Operations on these series still ignore NaN:
>>> nan_ser2.count() 1
Note
You can use the .astype method to convert columns to the nullable integer type. Just use the string 'Int64' as the type:
>>> nan_ser.astype('Int64')
Ono 2
Clapton <NA>
dtype: Int64
Similar to NumPy
The Series object behaves similarly to a NumPy array. As shown below, both types respond to index operations:
>>> import numpy as np >>> numpy_ser = np.array([145, 142, 38, 13]) >>> songs3[1] 142 >>> numpy_ser[1] 142
They both have methods in common:
>>> songs3.mean() 84.5 >>> numpy_ser.mean() 84.5
They also both have a notion of a boolean array. A boolean array is a series with the same index as the series you are working with that has boolean values. It can be used as a mask to filter out items. Normal Python lists do not support such fancy index operations:
>>> mask = songs3 > songs3.median() # boolean array >>> mask Paul True John True George False Ringo False Name: counts, dtype: bool
Once we have a mask, we can use that as a filter. We just need to pass the mask into an index operation. If the mask has a True value for a given index, the value is kept. Otherwise, the value is dropped. The mask above represents the locations that have a value higher than the median value of the series.
>>> songs3[mask] Paul 145 John 142 Name: counts, dtype: int64
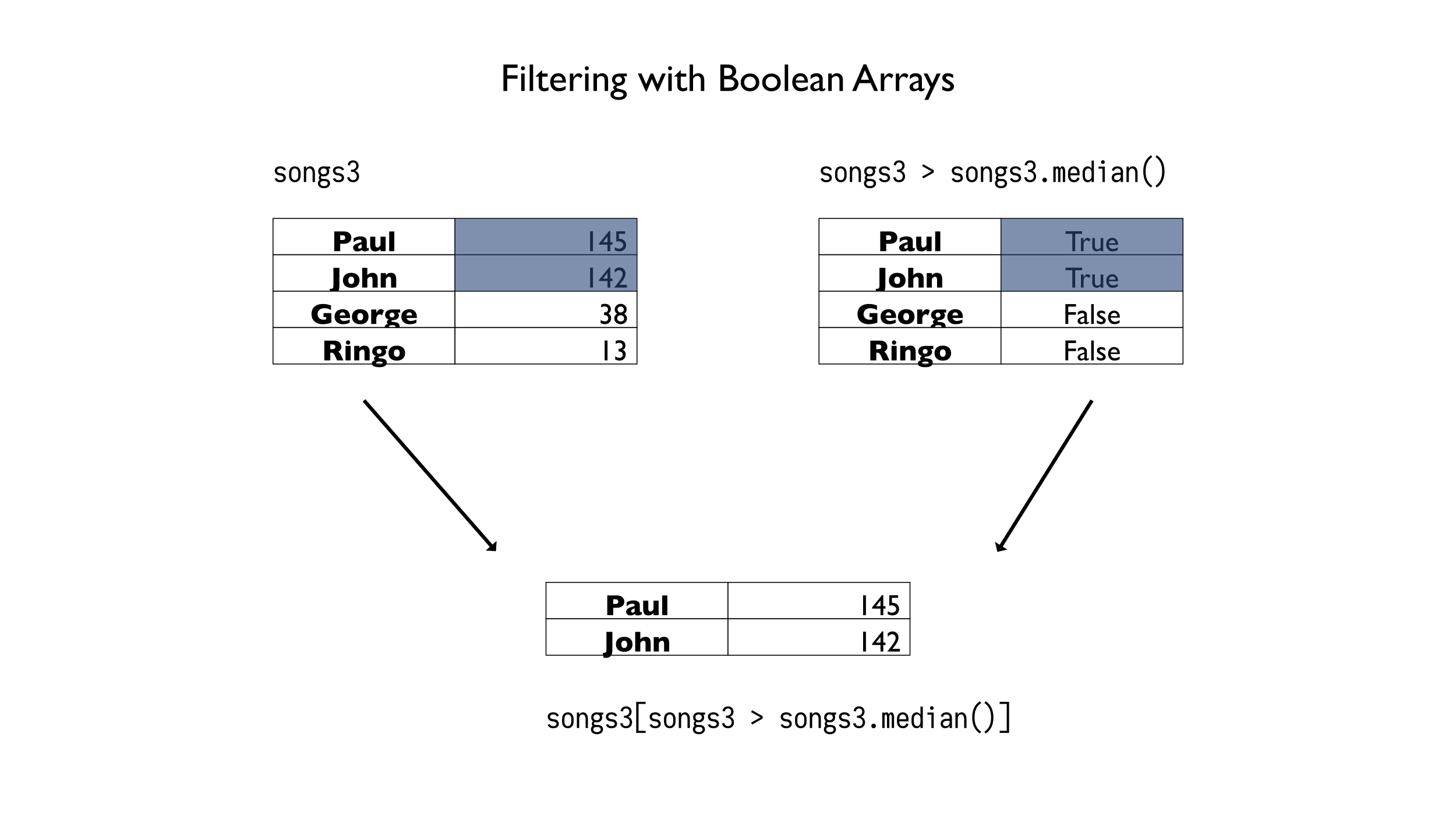
Filtering a series with a boolean array.
NumPy also has filtering by boolean arrays, but lacks the .median method on an array. Instead, NumPy provides a median function in the NumPy namespace:
>>> numpy_ser[numpy_ser > np.median(numpy_ser)] array([145, 142])
Note
Both NumPy and pandas have adopted the convention of using import statements in combination with an as statement to rename their imports to two letter acronyms:
>>> import pandas as pd >>> import numpy as np
Renaming imports provides a slight typing benefit (four fewer characters) while still allowing the user to be explicit with their namespaces.
Be careful, as you may see the following cast about in code samples, blogs, or documentation:
>>> from pandas import *
Though you see star imports frequently used in examples online, I would advise not to use star imports. I never use them in examples or my work. They have the potential to clobber items in your namespace and make tracing the source of a definition more difficult (especially if you have multiple star imports). As the Zen of Python states, “Explicit is better than implicit” [1].
| [1] | Type import this into an interpreter to see the Zen of Python. Or search for "PEP 20". |
Categorical Data
When you load data, you can indicate that the data is categorical. If we know that our data is limited to a few values; we might want to use categorical data. Categorical values have a few benefits:
- Use less memory than strings
- Can have an ordering
- Can perform operations on categories
- Enforce membership on values
Categories are not limited to strings; we can also use numbers or datetime values.
To create a category, we pass dtype="category" into the Series constructor. Alternatively, we can call the .as_type("category") method on a series:
>>> s = pd.Series(['m', 'l', 'xs', 's', 'xl'], dtype='category') >>> s 0 m 1 l 2 xs 3 s 4 xl dtype: category Categories (5, object): ['l', 'm', 's', 'xl', 'xs']
If this series represents size, there is a natural ordering as a small is less than a medium. By default, categories don't have an ordering. We can verify this by inspecting the .cat attribute that has various properties:
>>> s.cat.ordered False
To convert a non-categorical series to an ordered category, we can create a type with the CategoricalDtype constructor and the appropriate parameters. Then we pass this type into the .astype method:
>>> s2 = pd.Series(['m', 'l', 'xs', 's', 'xl']) >>> size_type = pd.api.types.CategoricalDtype( ... categories=['s','m','l'], ordered=True) >>> s3 = s2.astype(size_type) ... >>> s3 0 m 1 l 2 NaN 3 s 4 NaN dtype: category Categories (3, object): ['s' < 'm' < 'l']
In this case, we limited the categories to just 's', 'm', and 'l', but the data had values that were not in those categories. These extra values were replaced with NaN.
If we have ordered categories, we can do comparisons on them:
>>> s3 > 's' 0 True 1 True 2 False 3 False 4 False dtype: bool
The prior example created a new Series from existing data that was not categorical. We can also add ordering information to categorical data. We just need to make sure that we specify all of the members of the category or pandas will throw a ValueError:
>>> s.cat.reorder_categories(['xs','s','m','l', 'xl'], ... ordered=True) 0 m 1 l 2 xs 3 s 4 xl dtype: category Categories (5, object): ['xs' < 's' < 'm' < 'l' < 'xl']
Note
String and datetime series have a str and dt attribute that allow us to perform common operations specific to that type. If we convert these types to categorical types, we can still use the str or dt attributes on them:
>>> s3.str.upper() 0 M 1 L 2 NaN 3 S 4 NaN dtype: object
Summary
The Series object is a one-dimensional data structure. It can hold numerical data, time data, strings, or arbitrary Python objects. If you are dealing with numeric data, using pandas rather than a Python list will give you additional benefits. Pandas is faster, consumes less memory, and comes with built-in methods that are very useful to manipulate the data. Also, the index abstraction allows for accessing values by position or label. A Series can also have empty values and has some similarities to NumPy arrays. It is the basic workhorse of pandas; mastering it will pay dividends.