One of the keys to understanding pandas is to understand the data model. At the core of pandas are two data structures:
| Data Structure | Dimensionality | Spreadsheet Analog |
|---|---|---|
| Series | 1D | Column |
| DataFrame | 2D | Single Sheet |
The most widely used data structures are the Series and the DataFrame that deal with array data and tabular data, respectively. An analogy with the spreadsheet world illustrates the basic differences between these types. A DataFrame is similar to a sheet with rows and columns, while a Series is similar to a single column of data.
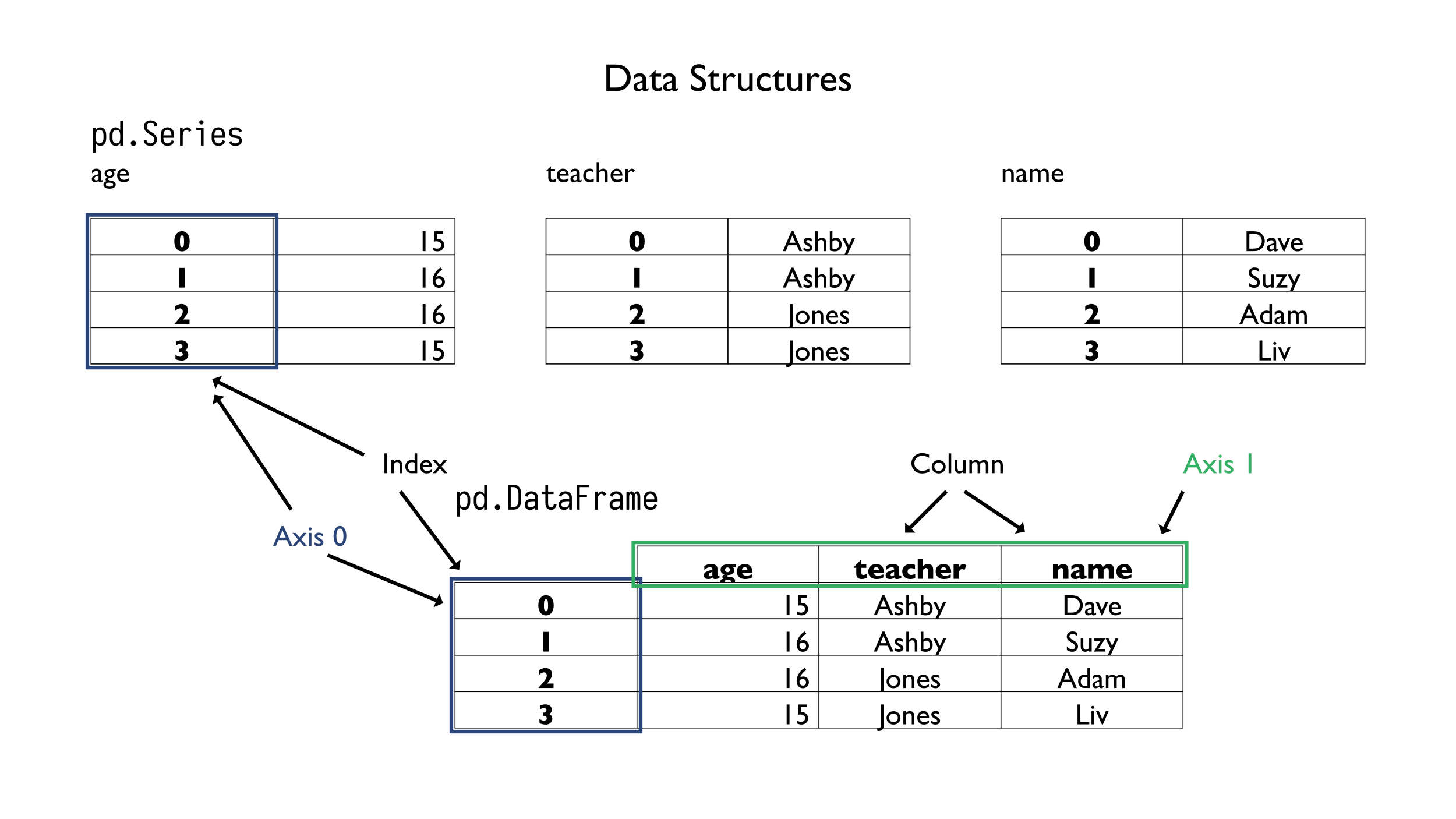
Figure showing the relation between the main data structures in pandas. Namely, that a data frame can have multiple series.
Diving into these core data structures a little more is useful because a bit of understanding goes a long way towards better use of the library. We will spend a good portion of time discussing the Series and DataFrame. Both the Series and DataFrame share features. For example, they both have an index, which we will need to examine to understand how pandas works.
Also, because the DataFrame can be thought of as a collection of columns that are really Series objects, it is imperative that we have a comprehensive study of the Series first. Additionally (and perhaps odd to some), we will see this when we iterate over rows, and the rows are represented as Series.
Note
Some have compared the data structures to Python lists or dictionaries, and I think this is a stretch that doesn't provide much benefit. Mapping the list and dictionary methods on top of pandas' data structures just leads to confusion.
Summary
The pandas library includes three main data structures and associated functions for manipulating them. This book will focus on the Series and DataFrame. First, we will look at the Series as the DataFrame can be thought of as a collection of Series.